It is easily obtainable by using PROC MEANS (or PROC SUMMARY). But when we face very large data with many varibles, we will hit memory wall and very long processing time using default options in PROC MEANS. The most time consuming and memory intensive descriptive statistics is quantile calculation. The default method uses ordered statistics, which is the most accurate but also the most memory intensive and time consuming one.
There are two methods available to handle this scenario, both uses the one-pass method of Jain R. and Chlamtac I [1]. This method is able to obtain fairly accurate estimate of quantiles between P25 and P75, but for quantiles outside this range, the estimates will be more rough but given very large sample, maybe acceptable. Another problem is that this estimator is sensitive to the distribution of underlying data [2]. There are newer methods available that are insensitive to the distribution, such as [3].
In PROC MEANS, we can specify QMETHOD=P2 or QMETHOD=HIST to call this one pass method. Or we can use PROC STDIZE, specifying PCTLMTD=ONEPASS to invoke P2 method to calculate quantiles. Each has its pro and con.
PROC MEANS:
PRO: Multithreaded / rich set of descriptive statistics;
CON: Only pre-defined quantiles, output data set is not user friendly, in need of further manipulation;
PROC STDIZE:
PRO: quantiles of 0 to 100 are available, statistics output data is in a user friendly format;
CON: No multithreads, lack of higher central moments statistics, need to surpress data output explicitly;
Of couse, due to the way the output statistics are organized from PROC STDIZE OUTSTAT=, it can be parallelized very easily, and by examining the actual CPU time, PROC STDIZE is more efficient than PROC MEANS. Besides, higher central moments can be calculated from obtained first 2 central moments and this is done in the small output data set.
Below the difference between default method and the two new approaches is illustrated.
options fullstimer;
data test;
length id 8;
array x{100} ;
do id=1 to 1e5;
do j=1 to dim(x); x[j]=rannor(0)*1.2; end;
output;
drop j;
end;
run;
proc means data=test noprint q1 qmethod=os;
var x1-x100;
output out=_mean
mean=mean1-mean100
std=std_x1-std_x100
q1=q1_x1-q1_x100
p95=p95_x1-p95_x100;
run;
proc means data=test noprint q1 qmethod=p2 qmarkers=211;
var x1-x100;
output out=_mean
mean=mean1-mean100
std=std_x1-std_x100
q1=q1_x1-q1_x100
p95=p95_x1-p95_x100;
run;
ods select none;
proc stdize data=test
out=_null_ outstat=_stat pctlmtd=onepass
nmarkers=211
pctlpts=1 5 10 25 50 75 90 95 99;
var x1-x100;
run;
ods select all;
Take a look at the log:
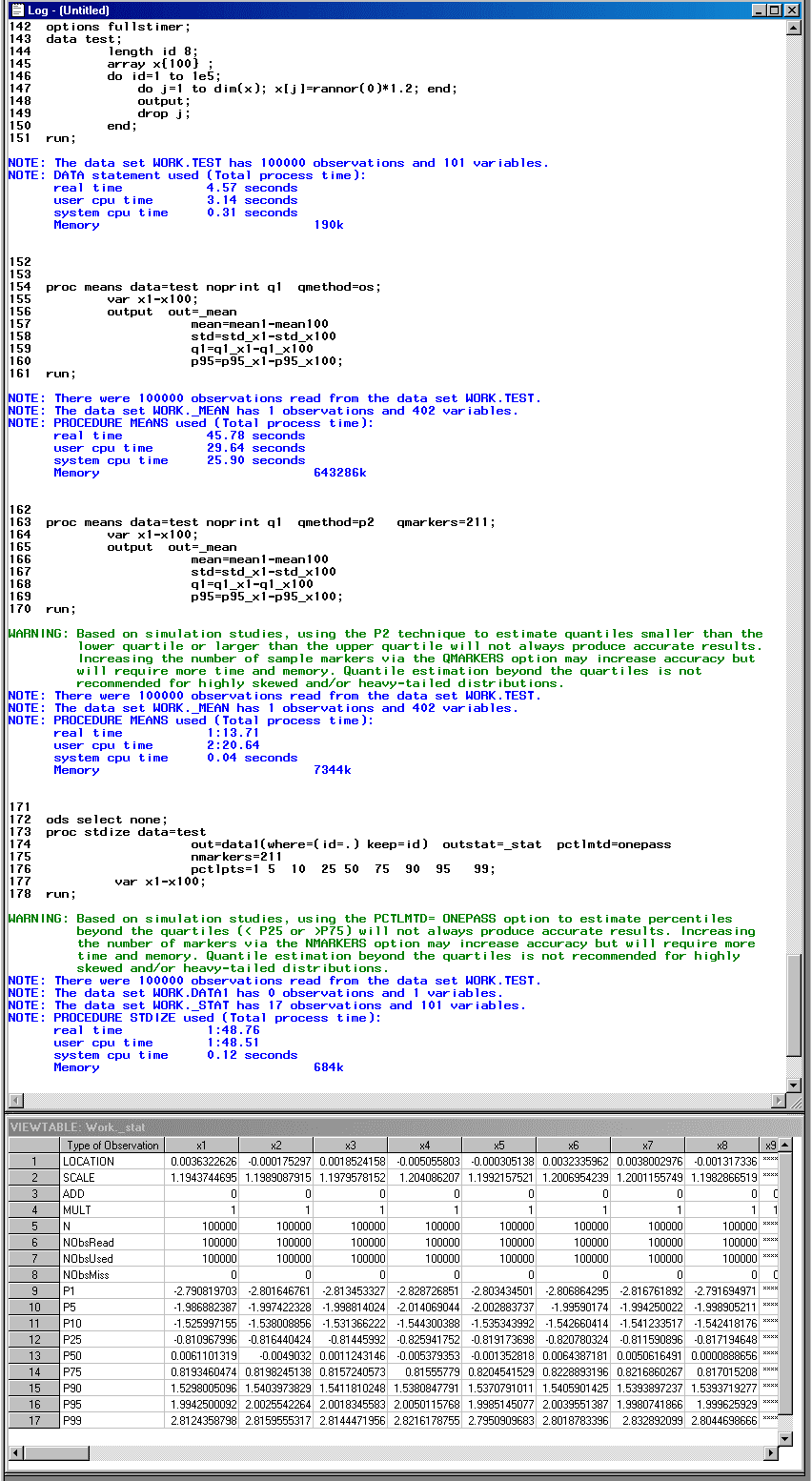
Due to smaller sample size, the most gain is on the memory side. Default approach of PROC MEANS used 643MB memory, which specifying QMETHOD=P2, the memory usage reduced to only 7.3MB. The most memory efficient is PROC STDIZE with PCTLMTD=ONEPASS, only 0.68MB memory was used.
We also examine the difference on quantile estimates using the Ordered Statistics (OS) method and P2 method in PROC MEANS. There are observable differences but not that significant:

Reference:
[1]. Jain R. and Chlamtac I. (1985), "The Algorithm for Dynamic Calculation of Quantiles and Histograms Without Storing Observations," Communications of the ACM, 28(10), 1076–1085.
[2]. SAS/STAT(R) 9.2 User's Guide, Second Edition
[3]. Alsabti, Khaled; Ranka, Sanjay; and Singh, Vineet (1997), "A One-Pass Algorithm for Accurately Estimating Quantiles for Disk-Resident Data". L.C. Smith College of Engineering and Computer Science - Former Departments, Centers, Institutes and Projects. Paper 4. http://surface.syr.edu/lcsmith_other/4